はじめに
1964 年に Nadaraya と Watson によって考案された Nadaraya-Watson は現在でも使われている手法です。カーネル平滑化の 1 つの手法であり、回帰手法の 1 つでもあり、局所線形回帰の兄弟のような関係を持っています。
本記事では、そんな Nadaraya-Watson を理解したいをコンセプトに書きました。
問題設定
Nadaraya-Watson について語る前に問題設定を書いておきます。
データセットが与えられているとします。は入力で、は出力です。
また、を新規の入力データとして、それに対応する出力をとします。
このときに、データセットを学習してとなるような滑らかな非線形写像を Nadaraya-Watson は推定します。
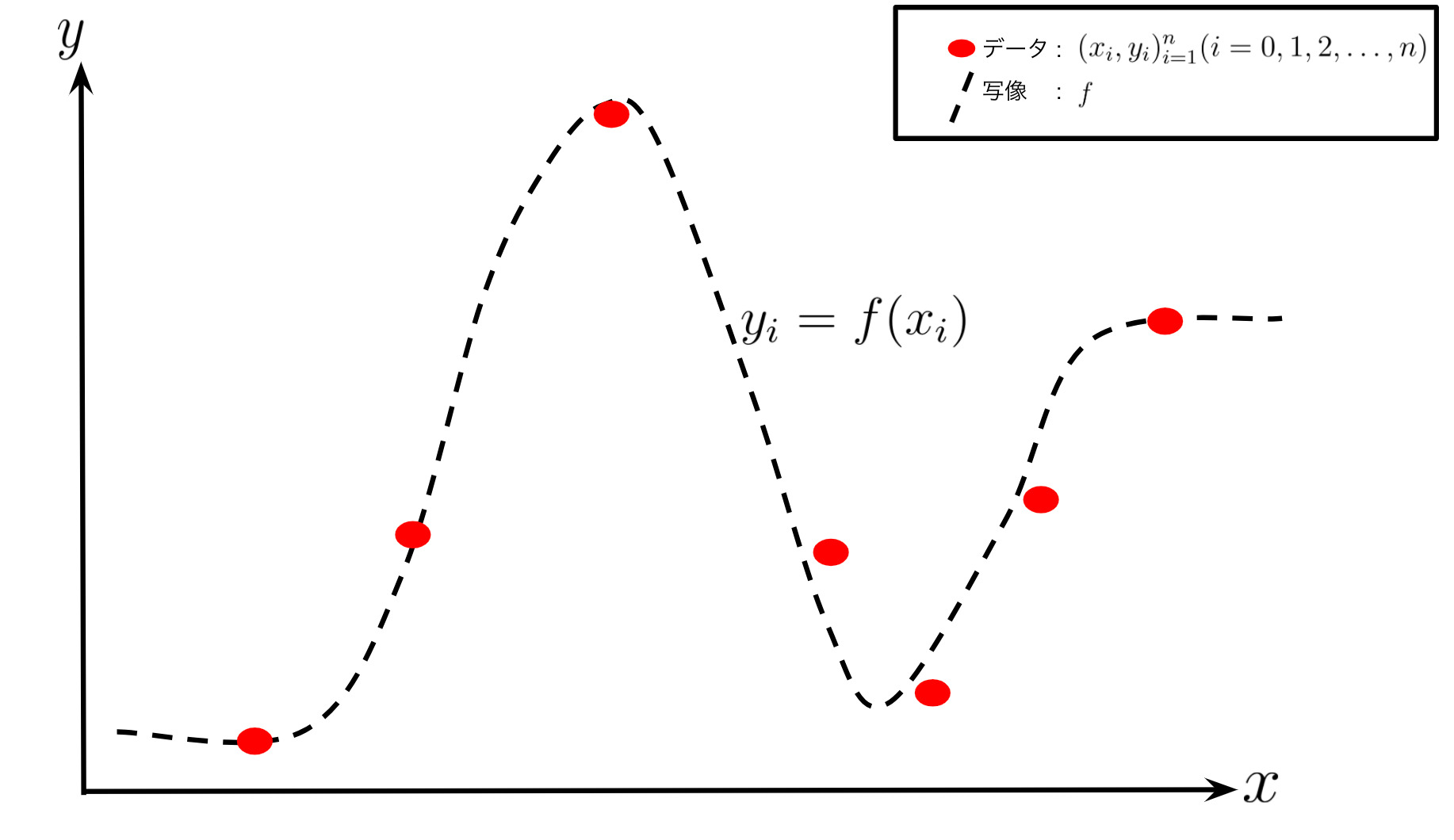
滑らかな非線形写像を Nadaraya-Watson は推定することで、図の波線部分が推定されます。
まずはざっくりと
まず、Nadaraya-Watson についてざっくりと書きたいと思います。
Nadaraya-Watson は、局所多項式回帰における第 0 次の局所線形回帰であり、0 次元カーネル平滑化と言われます。Nadaraya-Watson では、重み付け関数であるカーネルを用いて局所的に新規のデータと学習データの距離に応じた重みを与えます。その重み平均の平均を算出することで、新規の入力に対する出力の推定を行います。
わかりやすく言うと、重み付き平均における重みの決定にガウス関数を使っているということです。
非線形写像は下記の式で表されます。
は任意のカーネル関数であり、上記の式の場合はガウシアンカーネルです。新規のデータと学習データ,との距離に応じて重みを決定します。
Nadaraya-Watson は局所多項式回帰における第0次の局所線形回帰ですが、1 次になると局所線形回帰と言われます。第1次の局所線形回帰について詳しくはこちらに詳しく説明されています。
Nadaraya-Watson の位置付け
Nadaraya-Watson 推定はカーネル回帰でもあり、カーネル平滑化の 1 つの手法でもあり、カーネル密度推定とも関係しています。
Nadaraya-Watson 推定のカーネル回帰やカーネル平滑化、カーネル密度推定における位置付けを明確にしておきます。
カーネル回帰とは
カーネル回帰は、確率変数の条件付き期待値を推定するためのノンパラメトリック手法です。 目的は確率変数との非線形関係を見つけることになります。
ノンパラメトリック回帰では、変数に対する変数の条件付き期待値は次のように記述できます。
なぜこうなるのか?
サイコロの例で考える。
形の異なる二つのサイコロを投げて大きいほうのサイコロの目を、小さいほうのサイコロの目をとする。条件付き期待値を計算したい確率変数を 2 つのサイコロの目の積とし、という情報が分かっているとする。 このとき、ありうる可能性はの 6 通りであり、それぞれ確率 16 であるので
となる。同様にがわかっていると
というのが分かる、これは
というのが分かります。これを
と書くと、「の値が決まったときのの期待値はである。」と自然に読むことができる。このようなことは一般の確率変数の組 とが与えられた場合にもいえることで、関数をうまく見つけてきて
とすることができる。
この形から回帰手法として、Nadaraya-Watson 推定の式があるのです。
カーネル平滑化
カーネル平滑化は、近傍な観測データに対して局所的に重み付けをして単純なモデルをあてはめて実数値関数を推定するための統計手法です。
目的は、実数値関数を推定することからわかるように観測データを使って観測データの重要パターンや傾向を発見したり、予測をすることになります。
カーネル平滑化において、単純なモデルに直線(1 次)を当てはめるカーネル平滑化を 1 次のカーネル平滑化として局所線形回帰といいます。曲線(2 次)を当てはめれば 2 次のカーネル平滑化です。そして、N 次のカーネル平滑化は局所多項式回帰と呼ばれます。
Nadaraya-Watson 推定は、直線や曲線を当てはめずに単に観測データに対して局所的に平均をとるので 0 次のカーネル平滑化と言われています。
Nadaraya-Watson や局所線形回帰では、推定すべき回帰関数の曲率が大きいところでは比較的大きなバイアスが生じるデメリットがあります。分散の方を気にせずに、バイアスを縮小するなら局所多項式回帰を使います。
カーネル平滑化の目的と回帰手法の目的は一致します。また、上の文で回帰というワードが出てきていますように平滑化は回帰と見なせるので、カーネル回帰とカーネル平滑化は class="st-mymarker-s"断言はできませんが class="st-mymarker-s"ほぼ同じものと考えていいと思います。
カーネル密度推定
カーネル密度推定(KDE)は、確率変数の確率密度関数を推定するためのノンパラメトリックな方法です。を(未知の)確率密度関数を持つ独立同分布からのデータとして、その確率密度関数を推定します。各標本データの局所的近傍から得られる結果を重ね合わせて確率分布関数全体を推定(表現)しようとする特性上,標本データ数が少ないと正しい確率密度関数を得られない特徴があります。
カーネル密度推定は確率密度関数の推定方法、カーネル平滑化は回帰の手法です。 つまり、 カーネル平滑化とカーネル密度推定は別物です。
条件付き確率密度関数は、 のときに、次のように定義できます。
ここではとの同時分布で、は周辺分布です。これらは以下の式が成り立ちます。
したがって、これらを代入して変形していくと Nadaraya-Watson の式が導出されます。
二変量の同時分布をカーネル密度推定で推定した時、条件付き分布の平均値は Nadaraya-Watson と一致します。
Nadaraya-Watson の様々な呼び方
上記で述べたように Nadaraya-Watson はカーネル平滑化やカーネル回帰、カーネル密度推定と関係を持っています。ゆえに様々な呼び方で呼ばれます。その呼び方を以下にまとめておきます。
- Kernel smoother
- Kernel regression
- Nadaraya-Watson kernel estimator
- Nadaraya-Watson estimato
- Nadaraya-Watson kernel regression
何をしているのか
Nadaraya-Watson は重み付け関数であるカーネルを用いて局所的に新規のデータと学習データの距離に応じた重みを与えます。
つまり、新規のデータに近いデータに対しては誤差を重く、逆に遠いデータに対しては誤差を軽く見て推定を行います。
また、データの端点以降の写像は端点データに収束する特徴があります。
イメージ図は次のようになります。曲線が多少歪んで見えるかもしれないですが気にしないでください。
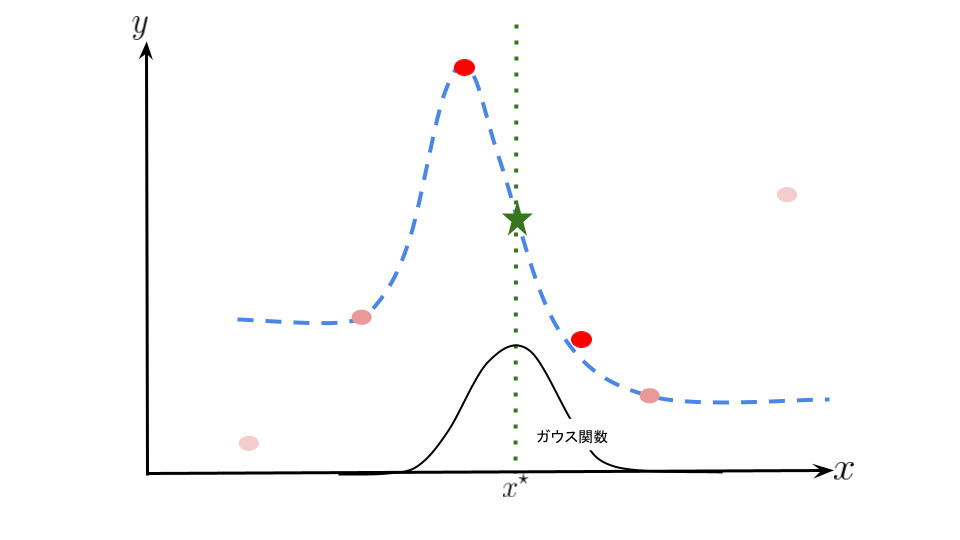
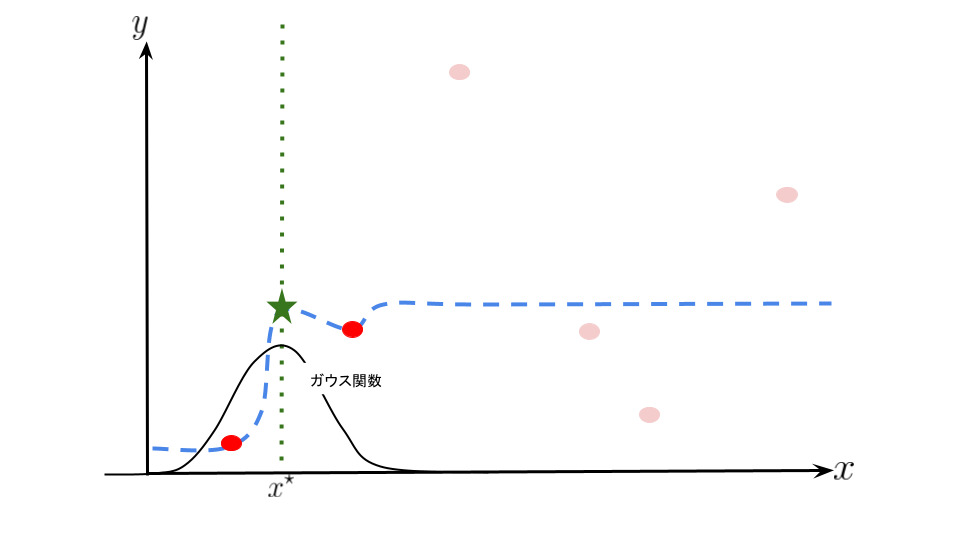
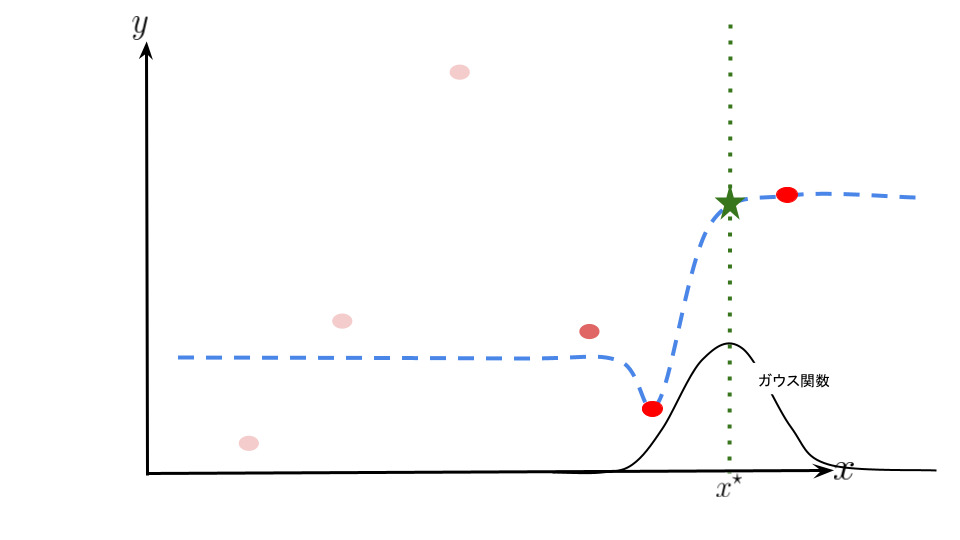
局所的に新規のデータと学習データの距離に応じた重みを与えることで写像の推定を行っているのがなんとなくイメージできたと思います。 Nadaraya-Watson では上記の青点線の組み合わせのような感じです。
このときの誤差の重みを決める関数(カーネル関数)は以下の式で表されるとします。
はカーネル幅と呼ばれる(ハイパー)パラメータです。ざっくり言いますと「新規データに対する近い or 遠いを決める境目」を決めるものです.これを大きくするとより広い範囲のデータを近傍と見なします.これを究極に大きくすると全てのデータ点に対する平均値しかとりません。
実装
それでは Nadaraya-Watoton を実装して挙動を見ていきたいと思います。
import numpy as np import matplotlib.pyplot as plt class NW(): def **init**(self, sigma): self.sigma = sigma def fit(self, x, y, test_x): delta = test_x[:, None] - x[None, :] #新規データ - 元データ Dist = np.square(delta) kernel = np.exp((-0.5 / (self.sigma \*_ 2)) _ Dist) #ガウシアンカーネル k_denominator = np.sum(kernel, axis=1) r = kernel / k_denominator[:, None] pred_y = r @ y return pred_y if **name** == '**main**': np.random.seed(0) train_x = np.linspace(-5, 5, 10) train_y = np.sin(train_x) + np.random.randn(\*train_x.shape) / 8 test_x = np.linspace(-6, 6, 100) #新規のデータ nw = NW(σ:=0.8) pred_y = nw.fit(train_x, train_y, test_x) fig = plt.figure() plt.scatter(train_x, train_y, c='b', lw=2, label="train") plt.legend() plt.xlabel('x') plt.ylabel('y') fig.savefig("img.png") plt.show()
データはに対してガウスノイズを加えたものを使います。
近傍半径、、でプロットした結果を貼っていきます。
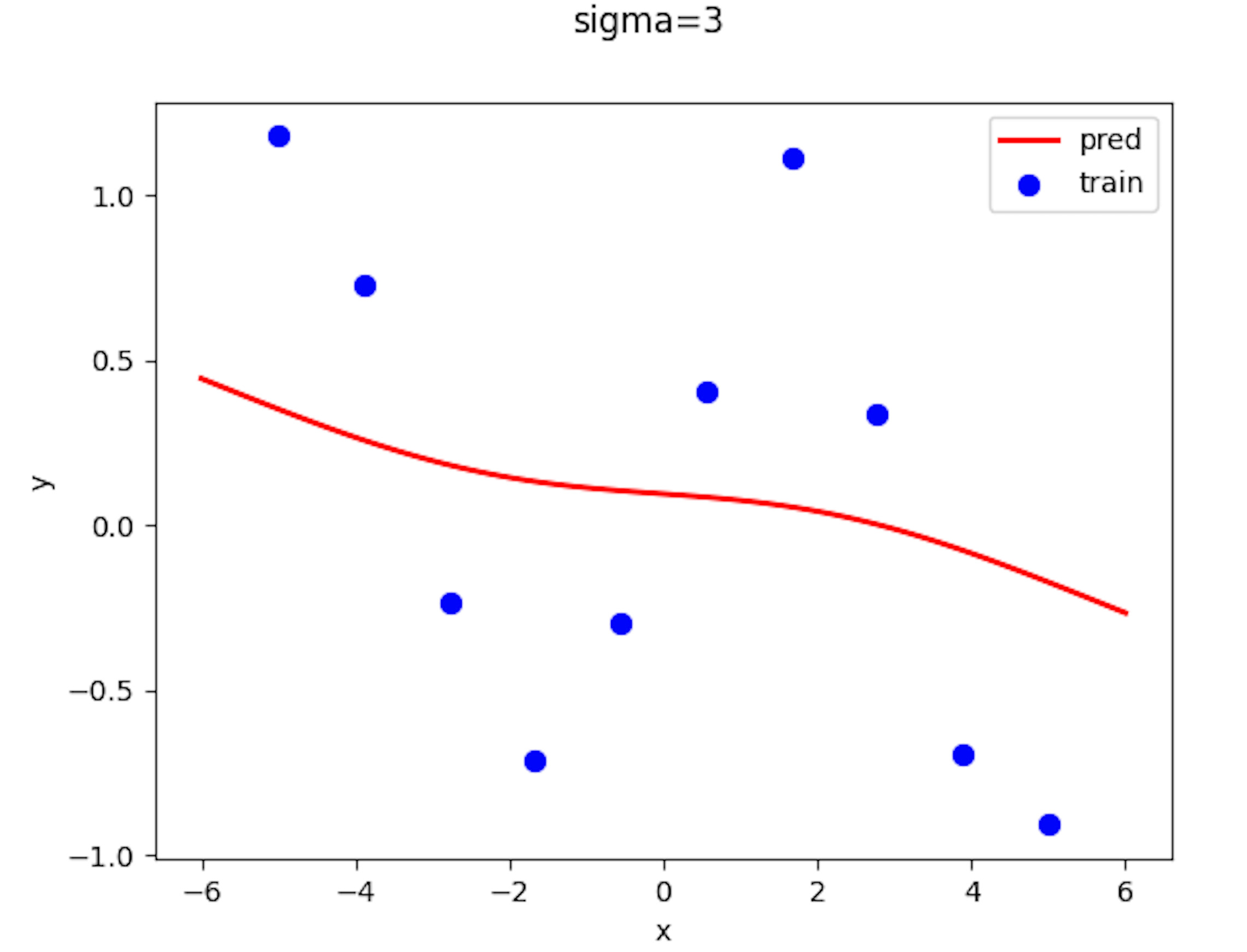
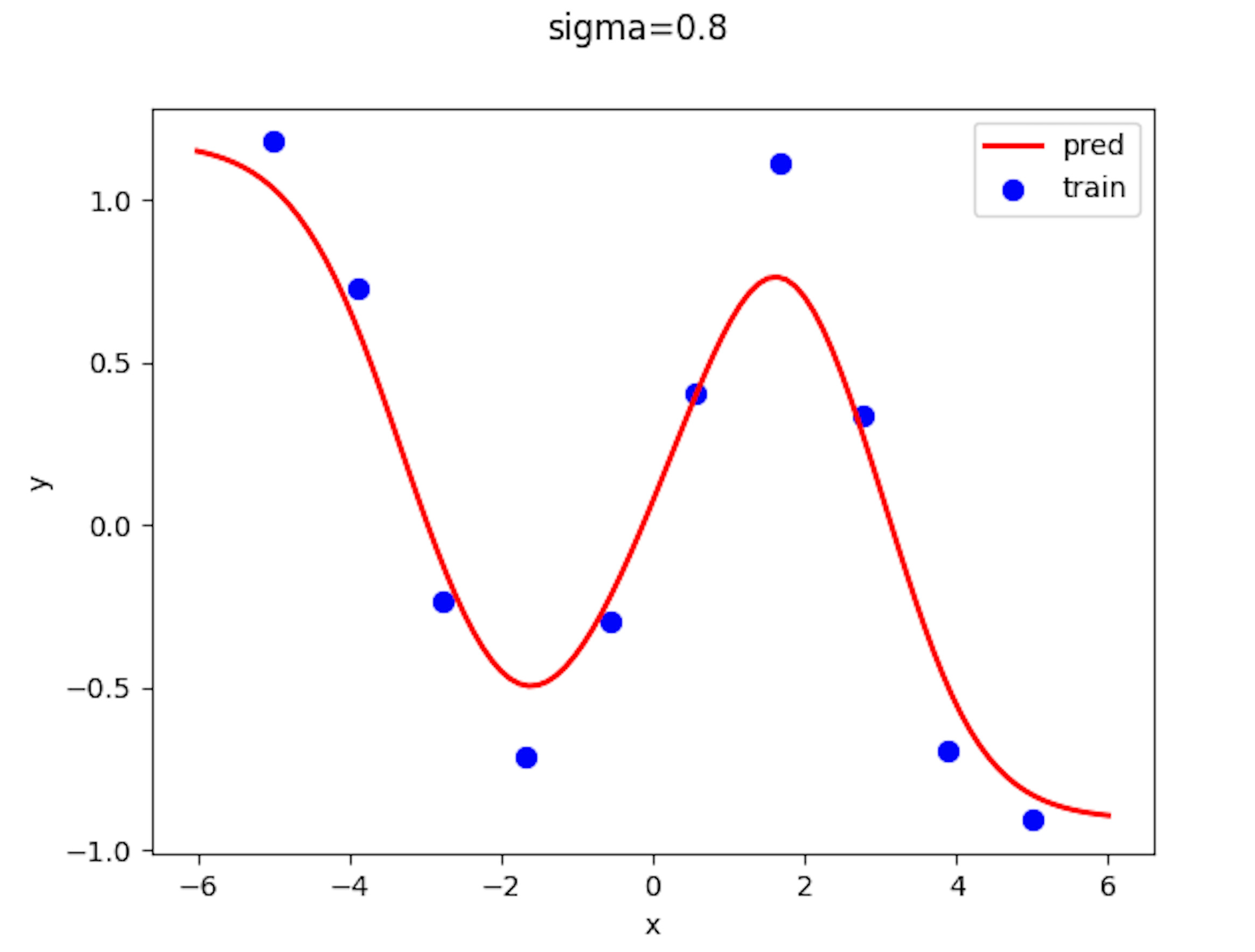
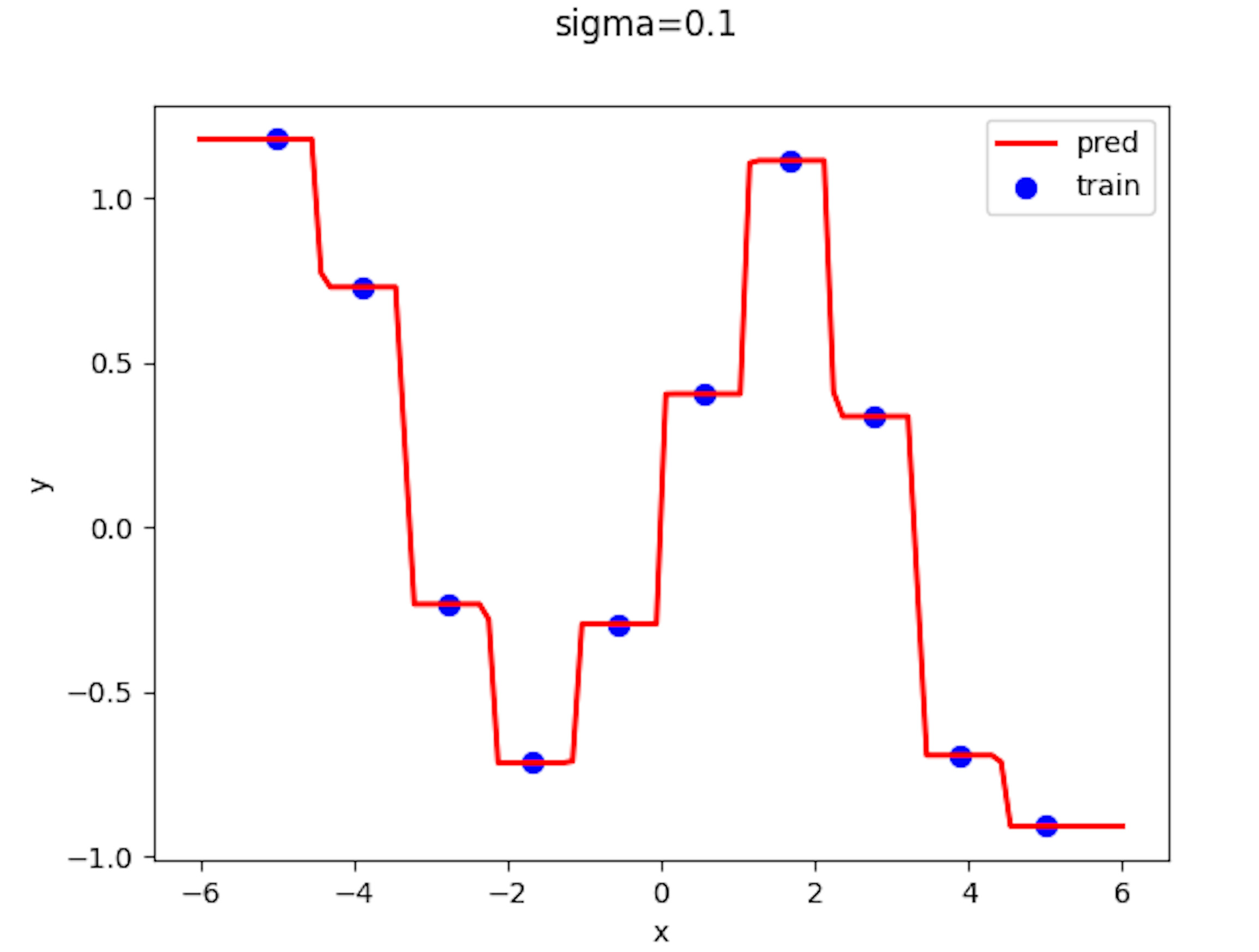
近傍半径がのとき推定値は入力に最も近いデータに対応するの値をとるようになっています。 これは、Nadaraya-Watson に次のことが成り立つからです。
入力、出力においてのとき,
近傍半径が小さすぎると、最も近い学習データにのみ影響を受け、その値になるのです。そのため、学習データ間の中間付近ではステップ関数のような挙動が見られるのです。これは、K 近傍法のの数 1 のときの結果と同じです。
最後に、近傍半径を小さくしていくとどうなるのかの動画を載せておきます。
最後に
ここまで読んでくださってありがとうございました。 編集リクエストもお待ちしてます。
こちらもオススメです。 ↓↓↓↓↓↓↓↓↓↓↓↓